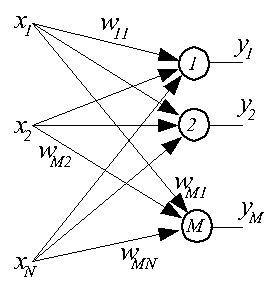
Сетями с самоорганизацией называются сети, не требующие для своего обучения "учителя" и самостоятельно адаптирующие свои веса под обучающие данные. Такие сети строятся из нейронов типа WTA и подобных им. Как правило, это однослойные сети, в которых каждый нейрон получает все компоненты входного вектора X размерностью N. На рисунке представлена структурная схема такой сети.
Веса входных связей i-ого нейрона образуют вектор
Кроме связей, явно представленных в схеме, на этапе обучения имеют место связи между нейронами, позволяющие судить о степени "соседства" нейронов друг с другом, при этом смысл понятия "соседство" может быть разным. Такие сети часто требуют нормализации значений входного вектора.
Укрупненно процесс обучения сети выглядит следующим образом. На вход сети подается обучающий вектор Xk, для каждого нейрона определяется d(Xk, Wi) - расстояние (в смысле выбранной метрики) между векторами Xk и Wi. Определяется нейрон-победитель, для которого это расстояние оказывается наименьшим. Вокруг нейрона-победителя образуется окрестность Skw из нейронов-соседей с известным "расстоянием" до победителя. Веса нейрона-победителя и веса его соседей из Skw уточняются, например, по правилу Кохонена
В качестве меры измерения расстояния между векторами чаще всего используются:
Экспериментальные исследования подтвердили необходимость нормализации входных векторов при малой размерности пространства (N<5), с увеличением размерности входного вектора эффект нормализации становится все менее заметным, а при больших векторах (N>200) она перестает оказывать влияние на процесс обучения и функционирования сети.
Для проведения нормализации предлагается два способа:
При использовании второго способа возникает, как правило, необходимость предварительного масштабирования компонентов исходного вектора X.
При "слепом" (как правило, случайном) выборе начальных значений весов часть нейронов может оказаться в области пространства, в которой отсутствуют обучающие данные или где их количество ничтожно мало. Такие нейроны имеют очень мало шансов на победу в конкурентной борьбе и адаптацию своих весов, вследствие чего они остаются мертвыми. В итоге уменьшается количество активных нейронов, участвующих в анализе входных данных, и, следовательно, увеличивается погрешность их интерпретации , называемая погрешностью квантования. Встает проблема активации всех нейронов сети на этапе обучения.
Такую активацию можно осуществить, базируясь на учете количества побед, одержанных каждым нейроном в ходе обучения. Существуют разные механизмы такого учета.
В одном из таких подходов каждому нейрону сети приписывается потенциал pi, значение которого модифицируется после предъявления каждого обучающего вектора Xk по следующей формуле (в ней w - индекс нейрона-победителя):
В другом подходе для выявления победителя в конкурентной борьбе предлагается использовать не фактические значения расстоянии между векторами d(Xk, Wi), а величины, промасштабированные количеством побед Nwi*d(Xk, Wi), где Nwi - количество побед, одержанных i-м нейроном к текущему моменту.
Как показали эксперименты, при использовании описанных выше механизмов двух-трех циклов обучения обычно достаточно для активации всех нейронов сети, поэтому в последующих циклах эти механизмы отключаются.
Целью обучения сети с самоорганизацией на основе конкуренции является минимизация погрешности квантования
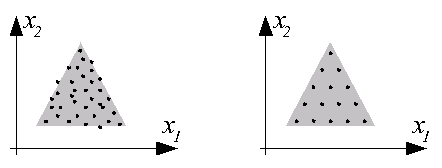
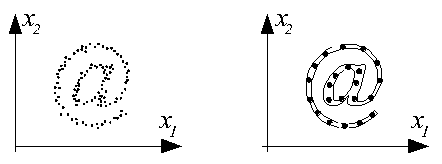
Примеры результатов обучения, близких к оптимальным, представлены ниже на рисунках. Используются сети с 15 и 22 нейронами и двухкомпонентным входным вектором X=[x1, x2]T. На левых рисунках представлено распределение данных в обучающих выборках, на правых - распределение весов нейронов обученной сети.
Для обучения сетей с самоорганизацией на основе конкуренции наибольшее распространение получили два описываемых ниже алгоритма.
В нейронных сетях, предложенных Т. Кохоненом (1982 г.), соседство нейронов носит топологический характер. В простом случае нейроны слоя Кохонена образуют одномерную цепочку, при этом каждый нейрон имеет, в общем случае, двух ближайших соседей (слева и справа). В более сложном случае нейроны Кохонена образуют двумерную сетку с четырьмя соседями у каждого нейрона (слева, справа, сверху, снизу). В еще более сложном случае сетка гексагональна - у каждого нейрона шесть соседей на плоскости (по циферблату часов - 2, 4, 6, 8, 10, 12 часов).
Коррекция весов нейронов в ходе обучения выполняется по формуле
Как обычно, коэффициент обучения nuki и параметр ширины функции Гаусса sk уменьшаются в ходе обучения (с ростом k).
В результате обучения слоя Кохонена по такому алгоритму топологически соседние нейроны становятся типичными представителями кластеров обучающих данных, соседствующих в многомерном пространстве. В этом достоинство сетей Кохонена, называемых также картами Кохонена, - наглядность в представлении (путем одномерной или двумерной визуализации) многомерных данных.
В этом алгоритме адаптация весов выполняется по той же формуле:
В каждом цикле обучения все нейроны сортируются в последовательности возрастания расстояния d(Xk, Wi)
Значение функции соседства i-ого нейрона Gk(i,Xk) определяется следующим выражением:
Для достижения хороших результатов самоорганизации сети обучение должно начинаться с большого значения sk, которое с течением времени обучения уменьшается до 0. Для такого уменьшения sk предлагается использовать выражение
Коэффициент обучения nuki тоже может уменьшаться с течением времени обучения, это уменьшение может быть линейным от numax в первом цикле до numin в цикле kmax, так и показательно в соответствии с формулой
Очевидным практическим приложением сетей с самоорганизацией является сжатие (с потерями) данных, в частности, покадровое сжатие изображений.
В процессе обучения сети последовательно предъявляются кадры изображения A. Похожие кадры обеспечивают победу одного и того же нейрона, корректирующего свои веса с сторону усреднения всех векторов входных данных, составляющих кластер "похожих" кадров. По окончании обучения веса каждого нейрона определяют образ некоторого "стереотипного" кадра.
При функционировании обученной сети в режиме компрессии данных ей предъявляются кадры сжимаемого изображения B. В результате расчета расстояний d(Xk,Wi) выявляется нейрон-победитель. Покадровая последовательность номеров нейронов-победителей вместе с весами всех нейронов сети и представляет собой сжатое изображение.
Декомпрессия (восстановление) изображения B легко реализуется "склеиванием" стереотипных образов нейронов, составляющих кодовую последовательность.
Желательно, чтобы обучающее изображение A и сжимаемое изображение B принадлежали одному типу (фотография, рисунок из учебника, чертеж, живопись и т.д.).
Важным свойством сетей с самоорганизацией на основе конкуренции является способность к кластеризации данных и их распознаванию. Это обеспечивает их широкое применение для решения задач диагностики, например, неисправностей оборудования.
Способность сетей с самоорганизацией на основе конкуренции представлять большие группы данных, объединенные в кластер, единственным вектором весов нейрона-победителя дает возможность строить высокоэффективные гибридные сети аппроксимации данных (для чего сети с самоорганизацией как таковые не приспособлены).
Структурная схема гибридной сети представлена ниже.
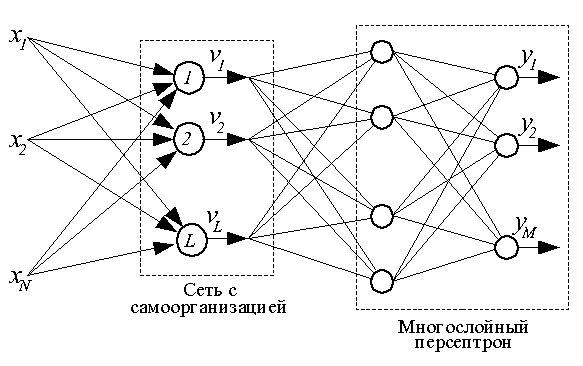
Обучение гибридной сети состоит из двух независимых этапов, следующих один за другим.
1. Сначала на множестве входных векторов стандартным образом обучается сеть с самоорганизацией. По завершении обучения веса всех нейронов фиксируются. В дальнейшем выходные сигналы нейронов рассчитываются следующим образом:
2. Далее стандартным образом обучается с учителем многослойный персептрон. Для обучения используются пары <Vk,Dk>, где Vk - это вектор выходных сигналов сети с самоорганизацией, полученный при подаче на ее вход вектора Xk из оригинальной пары <Xk,Dk>.